Thoughtware: The web app that writes itself
What if you never had to write application logic again?
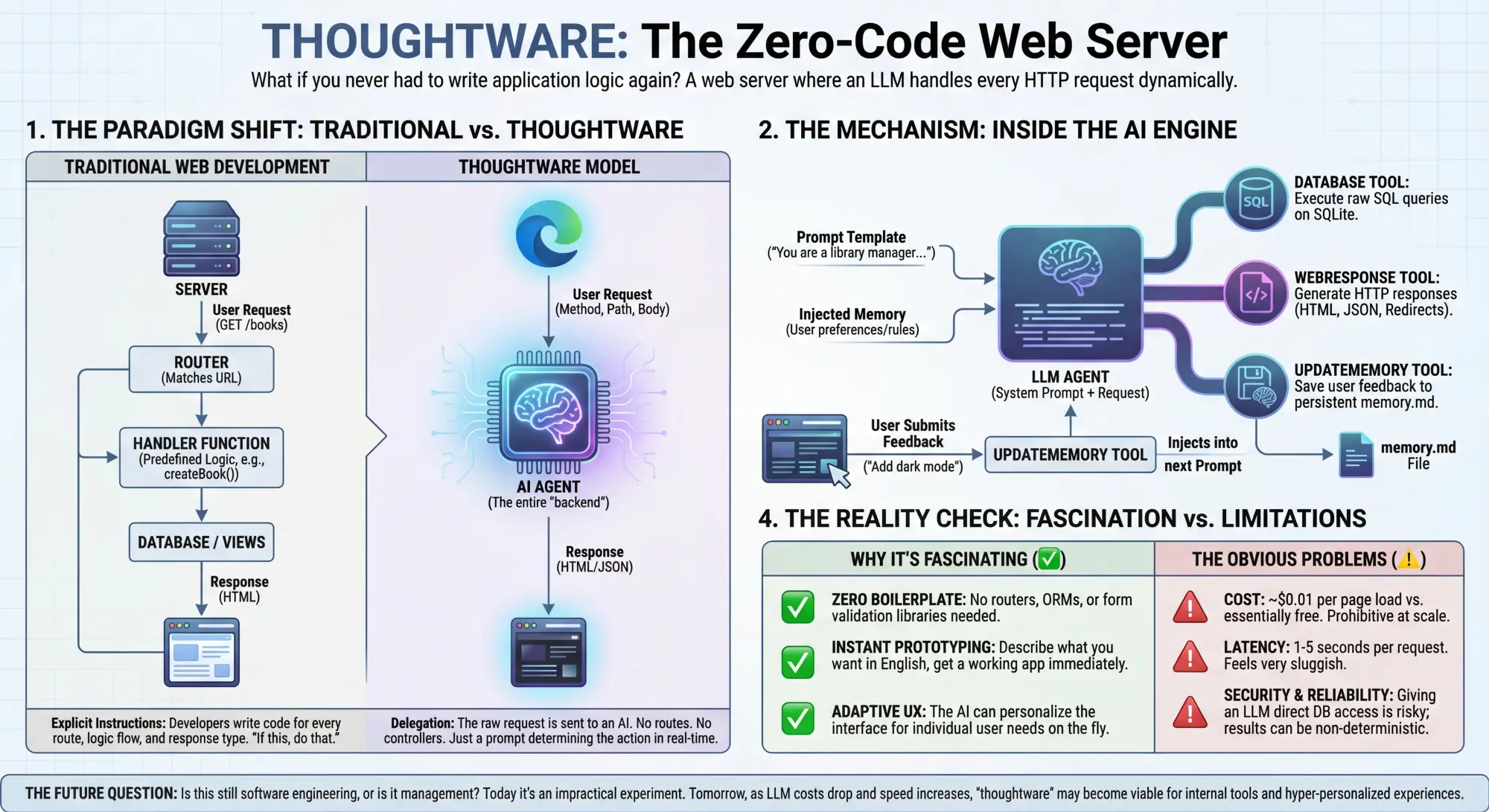
I recently showed that an agent can be built in 200 lines of code. What if we took that agent and have it handle web requests?
The result - a web server with zero application logic - is fascinating. It has no routes, no controllers, no business logic. Just a prompt and an AI agent that handles every HTTP request dynamically.
I call it thoughtware. You can find a demo on GitHub.
The Concept
Traditional web development follows a familiar pattern:
- User makes a request
- Router matches URL to handler function
- Handler executes predefined logic
- Response is returned
Thoughtware flips this entirely:
- User makes a request
- The entire request (method, path, query params, body) is sent to an LLM
- The LLM decides what to do and uses tools to generate a response
- Response is returned
There’s no application code. Just a thin server that forwards requests to an LLM and gives it three tools:
database: Execute SQL queries on SQLitewebResponse: Generate HTTP responses (HTML, JSON, redirects)updateMemory: Save user feedback and preferences
That’s it.
How It Works
The server loads a prompt template that describes what the application should do. For example, my test case is a library management system:
You are the backend for a living, evolving library management
application. You handle HTTP requests for a library management
system. Users can catalog, browse, check out, and manage books.
When a user visits /, the agent:
- Sees the request:
GET / - Reads the prompt explaining it’s a library manager
- Queries the database for books
- Generates a complete HTML page listing all books
- Sends it back via the
webResponsetool
When a user submits a form to create a book:
- Sees the request:
POST /bookswith form data - Inserts the book into the database
- Redirects to the home page
The LLM figures this all out on its own. There’s no /books route handler. No createBook() function. The AI interprets the request, decides what SQL to run, and generates appropriate HTML - all in real-time.
The Living Application
Here’s where it gets interesting: the application evolves based on user feedback.
Every page includes a feedback widget. When users submit feedback like “make the buttons bigger” or “add dark mode”, it’s saved to a memory.md file. This memory is then injected into the prompt for all future requests.
The LLM reads the memory and implements the changes. If someone requested dark mode, every subsequent page render will include dark mode styling. If someone wanted red buttons, the buttons become red.
The application literally changes itself based on user feedback, without any code changes.
Why This Is Fascinating
1. Zero Boilerplate
No routes. No ORMs. No form validation libraries. The LLM handles all of it through natural language instructions in the prompt.
2. Instant Prototyping
Want to add a new feature? Update the prompt. Want to change the UI? Give feedback through the app. The changes are live immediately - no deploys, no code reviews.
3. Natural Language as Code
The “codebase” is a prompt file. You describe what you want in English, and the LLM implements it. Version control becomes tracking changes to a markdown file.
4. Adaptive UX
Traditional apps have fixed UX. Thoughtware apps can adapt to individual user preferences automatically. One user wants dark mode, another wants large text - the LLM can potentially remember and personalise for each user.
The Obvious Problems
Let’s be honest about the limitations:
1. Cost
Every request costs API tokens. A traditional page load is essentially free (after server costs). A thoughtware page load costs $0.001-0.01 depending on complexity. At scale, this is prohibitively expensive.
2. Latency
LLM inference takes 1-5 seconds. Traditional handlers respond in milliseconds. The UX feels sluggish.
3. Reliability
LLMs are non-deterministic. The same request might produce slightly different results. Sometimes the LLM might hallucinate features that don’t exist or make mistakes in SQL queries.
4. Security
You’re essentially giving an LLM direct database access and control over your HTTP responses. This is clearly not secure.
5. Observability
Debugging is harder. You can’t set breakpoints or step through code. You have to read LLM logs and understand why it made certain decisions.
When Does This Make Sense?
Despite the problems, there are interesting use cases:
Internal tools: For low-traffic admin panels or internal dashboards, the cost and latency might be acceptable in exchange for zero development time.
Rapid prototyping: Build a working prototype in minutes by describing what you want. Once you validate the idea, rebuild it properly.
Personalised experiences: For applications where extreme personalisation is valuable, having an LLM dynamically generate each response could be worth the cost.
Educational tools: Imagine a learning platform where the LLM adapts the interface and content based on how the student learns best.
Accessibility: An LLM could dynamically adjust the UI for users with different accessibility needs without the developer manually implementing every variation.
The Philosophical Question
Thoughtware raises a deeper question: What is software?
Traditionally, software is explicit instructions: “if this, do that”. Thoughtware is more like delegation: “here’s what I want accomplished, figure out how”.
It’s less like programming and more like managing. You describe the goals and constraints, and the LLM figures out the implementation details on each request.
Is this still software engineering? Or is it something new?
The Future
Today, thoughtware is impractical. The costs and latency are too high, and its too unreliable.
But imagine a future where:
- LLM inference is 100x faster (Cerebras can already serve GPT OSS 120B at 3000 tokens/s)
- Costs drop 100x (token prices are falling dramatically year on year)
- Reliability improves with better models and agentic harnesses
In that future, thoughtware might become viable for certain classes of applications. Not everything (mission-critical systems will still need explicit code) but for rapid internal tools, personalised experiences, and experimental products, why write code when you could write a prompt?
Try It Yourself
The code is open source: github.com/samdobson/thoughtware
Clone it, add your API key, and watch an LLM hallucinate a web application in real-time. It’s a surreal experience to see it work.
The server is ~1000 lines of Python, and almost of that is:
- LLM client code (streaming, tool calling)
- Tool implementations (database, webResponse, memory)
The FastAPI app is nothing more than this:
@app.api_route(
"/{path:path}", methods=["GET", "POST", "PUT", "DELETE", "PATCH", "HEAD", "OPTIONS"]
)
async def catch_all(request: Request, path: str = ""):
"""Catch all routes and handle with LLM."""
return await handle_llm_request(request)
The actual application logic? Zero lines. It’s all in prompt.md:
You are the backend for a living library management application.
CURRENT REQUEST: {{METHOD}} {{PATH}}
Handle HTTP requests. Use the database tool for SQLite queries.
Use webResponse to return HTML/JSON. Use updateMemory to save
user feedback. Implement ALL feedback from memory. Include a
feedback widget on every page so the app evolves.
Conclusion
Thoughtware is an experiment in the extreme end of AI-assisted development. It asks the question: what if we wrote no code at all?
The answer is: amazingly, you can build working applications. Though you have to accept that they are slow and expensive.
But that’s today. The trajectory of LLM performance and cost suggests this might not always be true.
Maybe software is going to become thoughtware.
Inspired by the excellent Nokode project.